公開日:2024年6月6日最終更新日: 2024年6月6日
AWSで人気のデータ統合サービスにAWS Glueがあります。リリースされていない様々な機能追加や、変更が繰り返されていますが、非常に多機能なサービスとして注目されているものです。今までに利用した経験がある人もいるでしょう。
今までに経験がある人も含めて、AWS Glueの最新機能は改めて理解してもらいたいものです。常に進化を続けているサービスであるAWS Glueがどのようなものであるか解説していきます。
目次 <Contents>
AWS Glueとは
AWS GlueはAWSで提供されるサーバーレスでデータ統合を実現できるサービスです。AWS RedshiftやAWS S3などAWS内のデータを統合することはもちろん、AWS以外のデータソースを統合することも可能です。またデータの検出や加工といった事前準備にも対応しているため、統合したデータをデータ分析や機械学習など、別の用途に活用できます。
AWS Glueは多くの機能を持つため、その詳細については、以下で解説します。AWSの公式ブログには概要図が掲載されているため、参考に掲載すると以下のとおりです。
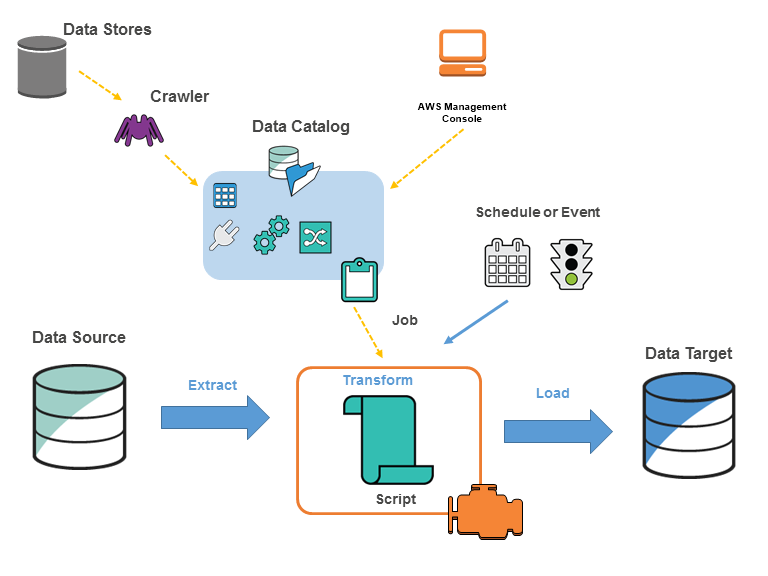
例えば、AWS GlueにはJobと呼ばれる機能が存在し、これを事前に設定しておくことで、自分たちでサーバーを構築することなくETLを実行できます。また、Glue Data CatalogはAmazon Athenaと統合されているなど、自然とデータ活用できる環境が整えられていることもポイントです。
AWS Glueの主な機能
AWS Glueにはいくつもの機能が用意されていますが現時点で必ず把握しておくべき内容は以下のとおりです。
ETLジョブ
AWS Glueを構成する重要な要素がETLジョブです。AWS RedshiftやAWS S3など、事前に定義されたソースからデータを抽出し、必要に応じてデータを加工します。また、その結果をDWHなど異なったサービスやツールへと連携する機能です。なお、具体的なジョブの設定方法には3種類が用意されています。
Spark Jobs
Apache Sparkと呼ばれるオープンソースのクラスタコンピューティングフレームワークを活用したETLです。クラスタを制御できるフレームワークであることから、活用することで大規模な分散処理を実装できます。大量のデータを処理したい場合などに良いでしょう。
設定にあたってはAWS Glueコンソールでスクリプトを記述する方法と、事前に作成しておいたスクリプトファイルをアップロードする方法があります。どちらの場合でもETLを実行するためのジョブ内容を作成することには違いがありません。設定さえ完了すれば、簡単にデータソースに対してETLの実行ができます。
なお、事前にライブラリが導入されているため、これを利用することで簡単に実装が可能です。また、pip3を利用して追加のライブラリを導入したり活用したりすることもできます。状況に応じてカスタマイズして利用すると良いでしょう。
Python Shell Jobs
Pythonで書かれたスクリプトを利用してETLを実行する方法です。上記のSpark Jobsと概要は同じですが、こちらは小規模なデータソースに対して利用します。ビッグデータに対して利用してしまうと、思うように動作しないことがあり得るため注意が必要です。
Pythonを実行する際にはサーバーレス・コンピューティングのAWS LambdaやコンテナのAWS Fargateが利用されることもあります。ただこれらと比較するとPython Shell Jobsはタイムアウト時間が長く設定されていることが特徴です。そのため、データ分析など処理が長くなりやすい状況に適しています。
ただ、クラスタ構成を利用して負荷分散するなどのアーキテクチャは実現できません。簡単なスクリプトを実行するならば良いですが、複雑になったりデータ量が多かったりする場合には注意しましょう。
Glue Studio
AWS GlueでのETLを素早く実装するために用意されたグラフィカルユーザーインターフェースです。画面上でコンポーネントを配置することで、簡単にETLジョブを作成できるようになっています。例えば、以下のような画面でETLジョブを設定できます。
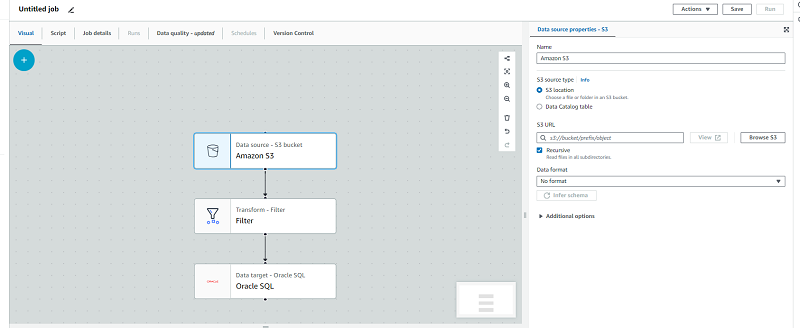
画像のとおり、データソースを指定してどのように加工するか(今回であればデータのフィルタ)を指定できます。また、加工したデータをどこに格納するかも画面上で設定できるのです。今回は非常にシンプルな構造になっていますが、複数のデータソースを結合したり、SQLを流してデータを加工したりすることもできます。
なお、スクリプトを自分で記述することもできますが、現状はユーザーインターフェースで作成することが望ましい印象です。細かな設定まで自動的に反映してくれるため、スクリプトを作成する際に記述漏れが発生するなどのトラブルを防いでくれます。
データカタログ
各種データがどこに保存されているかなど「メタデータ」と呼ばれるものを中心として、データカタログで管理できます。純粋にAWS Glueの処理で利用するだけではなく、Amazon AthenaやAmazon Redshiftからも参照される重要なデータです。
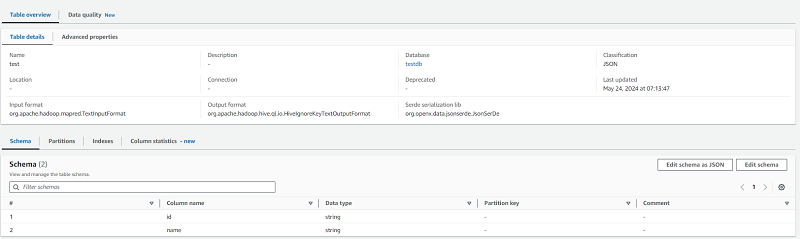
データが保存されているテーブルをまとめる機能ではありますが、これが用意されていることでデータを効率よく探しやすくなります。また、カラム名やデータ型などが明確になることで、処理を実装しやすくなるでしょう。他にも、階層化することによって、IAMなどによるアクセス制御を階層単位で実装しやすいなどの効果も生み出せるのです。
実際にデータカタログを利用する事例として、AWSのオンラインセミナーでは以下のようなベストプラクティスが紹介されています。
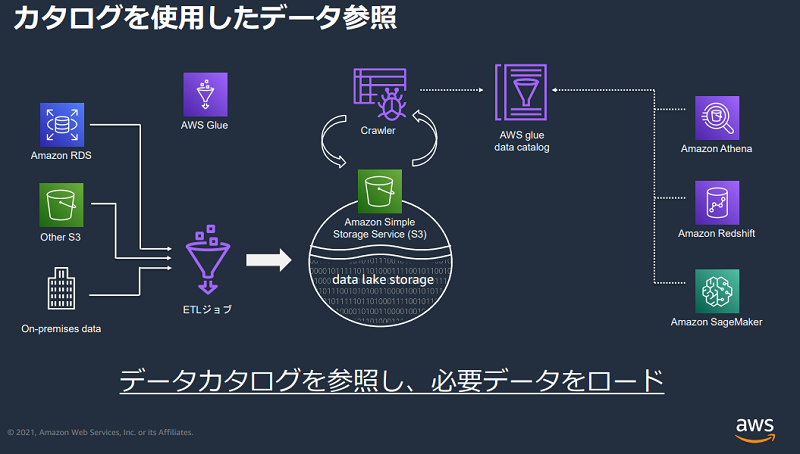
引用:[AWS Black Belt Online Seminar]AWS Glue
以下で解説するクローラーと組み合わせて、大量のデータを一元管理し、それを活用することを目的としているのです。
クローラー
Amazon S3やAmazon RDSなど、データファイルやデータベースから自動的に情報を収集してくる機能です。また、収集した情報を利用してデータの形式やスキーマなどをAWS Glueのテーブルに新規作成・追加・更新してくれます。
ただ、差分を収集することは可能ですが、差分が大きすぎる場合にはエラーとして扱われるため注意が必要です。大量のデータが変更されている場合には、削除してから新規作成として処理するなどの工夫が求められます。
収集のタイミングは手動実行と自動実行があり、定期的に情報が変更されるならば自動実行が良いでしょう。スケジュールを設定しておくことで、自動的にクローラーが動作して、情報を収集してくれます。
ワークフロー
ワークフローは、AWS Glueの機能を一連の流れで自動的に実行させるための仕組みです。例えば、複数のジョブを連続して実行したり、クローラーを実行してからジョブを実行するように設定したりできます。ワークフローのイメージは以下のとおりです。
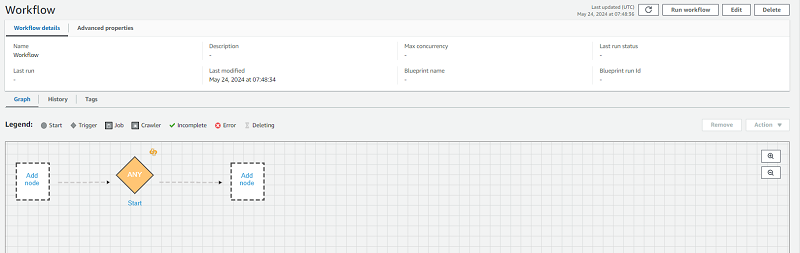
ジョブを設定したり追加で処理を導入したりできます。また、外部からのアクションをトリガーとして実行する必要があるならば、そのような設定を追加することも可能です。
ジョブだけではなくワークフローも用意されていることで、複雑なETLでも自動化が可能です。解説したとおり、ETLは画面上でジョブを設定できるようになっていますが、単体のジョブには限界があります。どうしても複数を組み合わせる必要がある場合に、ワークフローは大きな効果を発揮してくれるのです。
WS GlueとAWS Glue DataBrew
AWS Glueの派生サービスとしてAWS Glue DataBrewがあります。似ている名称ですが、それぞれ独立したものであるため注意が必要です。比較すると以下の違いがあります。
| 項目 | AWS Glue DataBrew | AWS Glue Studio |
| 事前に定義された処理 | 約250種類 | 約12種類 |
| ジョブの扱い | AWS Glue ジョブとは異なる独立したジョブ | AWS Glue ジョブ |
| ソースコードによるカスタマイズ | 不可能 | 可能 |
| UIの特徴 | データの中身を重視 | データソースやターゲットなど流れを重視 |
AWS Glue DataBrewは、データを準備するためのサービスで、コードを記述しなくともデータのクリーンアップを実現してくれます。例えば、データ解析や機械学習向けのデータを作成する際に、コードを記述することなく実装できるのです。一般的には複雑な実装が必要ですが、AWS Glue DataBrewならばその必要はありません。
ただ、事前に定義された処理が多いため、ソースコードによる個々のカスタマイズには対応していない点に注意しましょう。また「ジョブ」との名称が利用されていますが、AWS Glueとは異なる独立したものです。
AWS Glueを採用するメリット
データ分析にAWS Glueを採用するメリットについても解説します。
サーバーレスで環境を構築できる
最大のメリットは、サーバーレスでデータ分析の環境を構築できることです。本来は、サーバーを用意して専門的なアプリケーションをインストールする必要があります。しかし、AWS Glueならばサービスを有効化して簡単な設定を済ませるだけで、素早く環境の構築が完了するのです。
また、他のAWSサービスと簡単に連携できる環境であることも魅力でしょう。例えば、EC2にSSMエージェントをインストールして権限を付与しなくとも、S3からファイルを読み取りできます。エージェントのインストールや権限の設定が最小限に抑えられることもメリットなのです。
グラフィカルに設定できる
AWS Glueはスクリプトを利用したジョブの設定に対応していますが、グラフィカルな設定にも対応しています。直感的な操作で細かくETLを設定できることはメリットです。
もちろん、自分でプログラミングしてスクリプトを作成する方法も悪くはありません。しかし、このような作業は何かしら人的なミスを犯す可能性があります。対して、グラフィカルな設定画面を利用すると、このようなミスが起きる可能性を最小限に抑えられるのです。
例えば、データソースの名称が正しいかどうかチェックして、誤りがある場合はエラーとして示してくれます。手動でスクリプトを作成すると、このようなチェックは無く実行した際に気づくことになってしまうでしょう。いち早く検知できるという観点でもメリットがあります。
スケジュールやトリガー実行に対応している
手動で分析するだけではなく、スケジュールやトリガーによる自動実行にも対応していることがメリットです。頻繁にデータが更新されるなど手動での対応が難しい場合でも、AWS Glueならばスムーズに処理できます。
また、ワークフローの設定ができるため、自動的に次の処理に進むことも可能です。処理の対象となるデータが大量である場合「いつ処理が終わるか分からない」という状況に陥るでしょう。しかし、トリガー実行やワークフローを活用することで「処理が終われば次に進む」という部分も自動化できます。
まとめ
AWSでデータを効率よく統合するためのAWS Glueについて解説しました。進化を続けているサービスであり、これからも機能追加に期待できます。現状、いくつもの活用方法が考えられるため、まずは利用できるように概要を押さえておきましょう。
なお、AWS Glueで加工したデータは分析ツールなどに連携することが一般的です。そのため、AWS Glueについての理解が深まったならば、これらの知識習得にもチャレンジしてみましょう。
 お客様が運営するクラウドの監視・保守・運用業務を、ジードが代行いたします。
お客様が運営するクラウドの監視・保守・運用業務を、ジードが代行いたします。 お客様のご要望に沿って、適切なクラウド選定から設計・構築までを行います。
お客様のご要望に沿って、適切なクラウド選定から設計・構築までを行います。 Azure上で、AI + 機械学習、分析、ブロックチェーン、IoTを開発します。
Azure上で、AI + 機械学習、分析、ブロックチェーン、IoTを開発します。